
A few days ago David Harry published an excellent article on Google‘s RankBrain on The SEM Post. If you haven’t yet read it I’d put it in the “must read if you care about the future of search” category. It helps readers get a grasp on what RankBrain is and what it’s doing behind the scenes and you can find it here. Go on and read it. I’ll wait until you get back …
Excellent, with that under our belts, I’m going to be discussing a different but related patent that I happened to be reading the same day David’s article was published. The patent is titled, “Evaluating Semantic Interpretations Of A Search Query” and it outlines a method for extrapolating semantic relevance from a search query. Essentially, it outlines how a search engine could gain understanding of context for a given query when there are multiple possible meanings.
Interestingly, one of the greatest insights I got from this patent had nothing to do with the specific subject being discussed but rather a possible impact to rankings of clickthrough rate but I’ll get into that further below.
The Problem With Searchers
The problem Google is dealing with is that as searchers we often assume context when there is none inherently.
In the real world if I ask a question, the listener will have a context based on what’s going on at the time. Google does not have this advantage.
Here’s how they illustrate the problem:
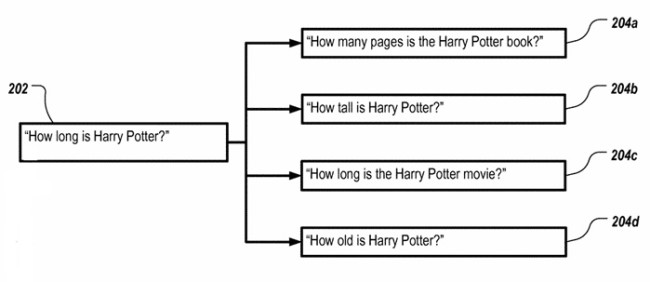
We have one query with multiple possible answers depending on the context. So how does the patent address this?
The Answer From Patent US 2016/0078131 A1
We’re going to start with Google’s diagram of the solution. It’s OK if you don’t get what it means, I didn’t before digging into the details but having seen the diagram helped me put a context to what I was reading so hopefully it’ll help you the same. If not, you can use it as a reference as you read further below.
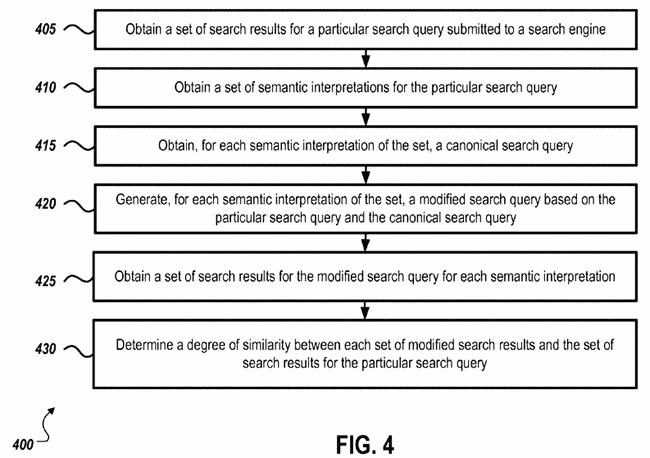
We can pretty much understand the purpose the patent by going through this image step-by-step so let’s do that.
Step One (405):
Obtain a set of search results for the given query. This is referring to the exact situation you would expect from classical search results when a query is entered and a result is returned based on relevance and site strength.
Step Two (410):
In step two the goal is to obtain a set of semantic interpretations (generally entities), that is – a list of all the possible meanings and contexts. In the case of the Harry Potter example that would include but definitely not be limited to:
- each Harry Potter book
- the character
- each of the Harry Potter movies
- each Harry Potter video game
- etc.
Step Three (415):
In step three they need to turn each result or entity from step two into a canonical query. For example, as Google works to determine the books that could be referenced, the entity “Harry Potter and the Goblet of Fire” would be included and it’s number of pages connected to it.
Essentially Google would build a semantic reference for each possible entity that could be deemed applicable by the initial search.
Step Four (420):
In step four Google turns each semantic interpretation into a more specific modified search query (a canonical query). An interesting point in the patent is the idea that a template can be created for different types of entities. That is to say that there could be a template query, “how many pages is the book <NAME OF BOOK ENTITY>” which is referenced to answer the question of how long “Harry Potter and the Goblet of Fire” is. There are other ways it can be done but the root is, a canonical query would be generated for each semantically related entity based on its type.
Step Five (425):
In step five a result set is produced for each canonical query (such as “how many pages in the book Harry Potter and the Goblet of Fire”).
Step Six (430):
In step six the system then needs to determine the degree of similarity between the various modified search results and the set of search results for the initial query to assign what is referred to as a “confidence score” to the new results. While this does assume that the result set most similar to that of the initial query is most likely right (which may or may not be the case) it does allow for adjustments based on user interactions as we will get into shortly so one can assume the similarity assumption is only in place as a starting point.
What Does This Really Mean?
In essence what the patent describes is a system by which every plausible interpretation of a query would be analyzed. The resulting data sets would be compared with the results of the initial query and as a confidence score assigned to each based on how similar it is. From there the most likely result would be selected to display to the user. As an aside, the patent does allow for the storing of the results sets and conclusions/calculations so that the full process does not need to be performed on the same or very similar queries in the future thus reducing the server burden from such a complicated process.
The question then becomes, “What if the conclusion is wrong?” That is to say, what if the confidence score is assigned to the wrong interpretation and the wrong canonical query is selected as the likely one to fit the intent of the searcher? While the entire patent is interesting it’s answering this question that caused me to think about clickthroughs in a completely different way.
Clickthroughs Don’t Affect A Site’s Ranking … They Affect Rankings
There’s always been a debate as to whether clickthrough rates can and do affect a site’s ranking. Google has often asserted that it is too easy to manipulate while testing has shown that it can have an impact. Take from this all what you will, either way a high clickthrough rate is good because the whole purpose of ranking to begin with is not bragging rights, it’s traffic. The patent however covers an interesting perspective I had honestly never thought of before.
In the patent it’s written:
“Using search results to evaluate the different semantic interpretations, other data sources such as click-through data, user-specific data, and others that are utilized when producing the search results are taken into account without the need to perform additional analysis.”
What this means (in the full context of the patent itself) is that the clickthrough rate on a result set can be used to determine if the entity selected to build the canonical query and resulting result was indeed correct. This takes the question of clickthrough rate well beyond whether it impacts an individual site’s rankings and into the realm of the entire result set being valid or not and, if not, a completely different interpretation chosen.
This means that if you notice a site going up or down in the rankings it may have little or nothing to do with the individual clichthrough rate or even relevancy to a subject, but rather a completely different interpretation of the same query. This is huge.
What this means for the site owner is that a ranking for “how long is harry Potter” may fluctuate not based on whether the site is optimized for the term but rather based on whether the site is relevant for a specific interpretation. Let’s assume it has a great page on “Harry Potter and the Goblet of Fire”. If this is the interpretation that Google selects as most likely out of the gate then the page will rank well however if the results as a whole have a poor signal then the engine may be determine that the initial assumption was incorrect and switch to a different interpretation (“how long is Harry Potter and the Philosophers’ Stone” for example). The site in question will drop in rankings in this instance however no amount of onsite SEO will repair that and only a page on the other movie will.
I don’t know about you but to me this is a significant idea that should be a strong consideration in content development strategies. If you want to rank for a phrase, have excellent content on the variety of related semantically similar terms. You probably should anyways to serve your visitors but if not for them, then for your ability to rank across a variety of semantic permutations.
Conclusion
While I always try to remember that patents are ideas and they may never be integrated into the algorithm, this one seems more likely than many to play some part. The ideas contained within it make sense in a world where AI is taking over and RankBrain will likely be expanded to the general algorithm in the near future. In the end, the only real action by the site owner is to produce an array of relevant and high-quality content on the subject it is built to rank for and if that’s the only “action item” on the list … it should be in the to-dos regardless.
So get going.
Really interesting to read. Its a long run for this patent to go live. But it will really change the SERP in future once Google comes to conclusion.