
Our regular readers will know what a fan I am of Google patents but even still, even now and then one crosses my radar that really gets me excited. Setting aside the incredible nerdiness of that first sentence let’s look at the latest patent to do that. The patent, titled “Ranking Search Results Based On Entity Metrics” gives very interesting insight into how Google treats entities.
Before we get into the patent itself, let’s first define what an entity is and think about why it’s important. According to the patent an entity is:
Entity: a thing or concept that is singular, unique, well-defined and distinguishable.
They go on to give examples noting that, “… an entity may be a person, place, item, idea, abstract concept, concrete element, other suitable thing, or any combination thereof. For example, the color “Blue,” the city “San Francisco,” and the imaginary animal “Unicorn” may each be entities.” It’s worth noting that an entity does not have to be a noun nor does it have to be real, it simply needs to be something that is understood to be unique unto itself.
With this all understood, let’s get into it …
Ranking Search Results Based On Entity Metrics
Patent: US 2015/0331866 A1
Title: Ranking Search Results Based On Entity Metrics
Publication Date: November 19, 2015
Filing Date: December 12, 2012
Abstract: Methods, systems, and computer-readable media are provided for ranking search results. A search system may determine several metrics based on search results. The search system may determine weights for the metrics, wherein the weights are based in part on the type of entity included in the search. The search system may determine a score by combining the metrics and the weights. The search system may rank search results based on the score.
The abstract itself gives little away about what follows. So let’s get to the good part, what this all means. To do this I’m going to define some of the critical areas of the patent. Following that I’ll be summarizing why I believe it’s important and what it tells us we need to do.
Section 14: In section 14 we get our first reference to the metrics that are being used in this patent. It reads, “In some implementations, the system makes use of four particular metrics: a relatedness metric, a notable entity type metric, a contribution metric, and a prize metric.”
If we took only one thing away from this patent it would be this single statement as it tells us an enormous amount about what an entity score is based on. That is:
- relatedness
- notability
- contribution
- prize
Section 17: In section 17 we cover the first in the list (relatedness) via co-occurrences. We have to understand that while there are a lot of people working at Google, they don’t have enough to create every connection between every entity and what it’s related to and why. For this reason they need to build in the ability for their system to learn which entities relate to others and what characteristics they have via co-occurrences. In this section they define this process as, “… where the search query contains the entity reference “Empire State Building,” which is determined to be of the entity type “Skyscraper,” the co-occurrence of the text “Empire State Building” and “Skyscraper” in webpages may determine the relatedness metric.”
Essentially what we’re to understand here is that the use of words on pages can help establish a connection between those two things. In their example, the use of the text “Empire State Building” and “Skyscraper” occurring together frequently reinforces that they are related. In fact, at the time of this writing there are 459,000 web pages reinforcing this point and now this post adds yet another.
Section 19: Jumping to the contribution metric the patent reads, “In some implementations, the contribution metric is based on critical reviews, fame rankings, and other information. In some implementations, rankings are weighted such that the highest values contribute most heavily to the metric.”
This idea ties directly to the fourth metric, the prize metric as we read in
Section 20: In the next section the prize metric is discussed. Where the contribution metric itself is a measurement of an entity’s contribution to a category, the prize metric is meant to be a metric to determine their value within that grouping. We can see this where it’s written, “The prize metric is based on an entity’s awards and prizes. For example, a movie may have been awarded a variety of awards such as Oscars and Golden Globes, each with a particular value. In some implementations, the prize metric is weighted such that the highest values contribute most heavily to the metric.”
This does lead to the question as to how the decision is made as to which “prizes” are to hold the higher values (for example, as an actor is an Oscar or a Golden Globe more valuable and perhaps more importantly, as a searcher – which prize impacts their value to me more?) That question is not answered in the patent though presumably there would need to be a manual aspect for core prizes and an automated mechanism to determine the value of those prizes that were not manually pre-defined.We’re going to have to jump ahead in the patent to cover the fourth metric which isn’t discussed until …
Section 40: In section 40 we encounter the description of what they are referring to as “notability” when it’s written:
“… the search system determines a notable entity typemetric N. In some implementations, a notable entity typemetric includes information related the notability of a search result. In some implementations, a notable entity typemetric N may be determined as N = G/n where G is a global popularity metric and n is a notable entity type rank. In some implementations, the global popularity metric G includes, for example, a ranking value based on aggregated user selections of entity references and/or data associated with entity references. In an example, a global popularity metric includes the likeliness that a particular search result generated in response to a similar search query will be selected by a random user for further browsing. The global popularity metric may also include the number of links to a particular search result, the number of links from a particular search result, the number of visits to a particular search result, any other suitable statistical information related to site visits and connectedness, or any combination thereof. In some implementations, the global popularity metric may include a ranking that would be used to order results by a web search engine.”
To fully break this down we also need to understand what’s noted in
Section 41: In this section we read the characteristics of the n (or notability entity type rank) in the formula where they write:
“In some implementations, notable entity type rank n includes a ranking of entity types within a domain. For a domain, the collection of types may be ranked by their notability, popularity, frequency of occurrence, any other suitable ranking, or any combination thereof. For example, “short stories,” “novels,” and “non-fiction” may be entity types in the domain “books.” The entity types may be ranked in the order “novels” followed by “non-fiction” followed by “short stories” assuming that novels are the most notable and short stories are the least notable. An entity type may be assigned the notable entity type rank n when it is in the position in the ranked list. For example, the fifth item in a list may be assigned the rank n. In some implementations, more complex relationships between one or more ranked lists and the notable entity type rank n may be used. For example, the rank may be scaled, normalized, combined with other metrics, determined by any other suitable technique, or any combination thereof.”
IMPORTANT !!!
It’s of critical important that we understand that the word “domain” in this instance is NOT being used as we would generally use it. It is not a reference to URLs or websites but rather a reference to a topical domain. That is, the domain of books could be sub-divided into the entity types of “novels” and “short stories”.
FURTHER
While you are reading the explanation below it’s important to understand that the Entity Notability metric is being assigned to the entity to be ranked BUT it is not the only entity being discussed which can make the explanation a bit confusing. The n (Entity Metrics) is referring to the Entity Type being searched, not the entity to be ranked. To give a simple example, if you are searching “best restaurant” there is the entity “restaurant” (which is the entity being referenced in the formula as n) and there is the entity to be ranked (the specific restaurants that are ranked) which are the variable N. Alright … let’s continue …
Reading these sections is fairly technical so let’s first break down the formula they reference and then simplify what they’re saying. The formula N = G/n simply means Entity Notability = Global Popularity / Entity Metrics. Alright, that might not have helped a lot until we think about what they’re trying to measure and what information they’re trying to get. What Google wants to know is what is the notability value of a specific entity to a query. That value will be N in the formula. To get a full grasp of the picture they also need to know the Global Popularity of an entity for the same or similar information sets. That is, they need to determine whether a specific entity is likely to provide the information requested based on elements like links, previous rankings and user metrics from traffic related to similar queries, etc. This makes up the variable G. The remaining variable is n which is the variable used to determine the weighting of the Global Popularity metric.
Here we see a ranking of specific entity types within a domain (remember … not a website domain). The more important an entity type is within a domain will impact the score n that it is assigned creating a scenario where a more important entity type (for example a novel over a short story) would impact the Entity Notability weight (the weight actually being assigned to the entity to be ranked). This can happen in a variety of ways but in one example a lower Entity Metric (n) could be assigned to less significant entity types. To use their example, if a value of 10 was assigned to the top entity type (novels) then a value of 6 could be assigned to “short stories”. Since we’re dividing by a smaller number now this would essentially produce a larger Entity Notability score in scenarios where the entity type is less important.
In real world terms this would create a scenario where a larger score would be assigned to entities that have a large Global Popularity (ex – links) for terms where there is less importance thus making “less important” entity types more susceptible to producing rankings from sites with higher Global Popularity metrics. You could think of a site like Wikipedia or large brands here holding a bigger advantage in less important areas and less of an advantage in more important ones. I’m not suggesting this is the case – this was simply an illustration to put a complex idea into real-world terms.
And Back …
You’ll remember that above I had to jump from Section 20 to Section 40 to keep all the information related to the four main metrics together. Between these two sections however there is some interesting information, critical for people who care about rankings (less call them … “you” and “I”).
Section 31: In section 31 we read, “In some implementations, elements of a domain share common characteristics, properties, traits, categorization techniques, any other suitable parameters, or any combination thereof. In an example, domains include “Books,” “Film,” “People,” and “Places.” Entity types within the domain “Movies” may include: “Actor,” “Director,” and “Filming Location.”
This is an aspect of SEO and entities we’ve all probably known for years but worth seeing confirmed. Entity types are related and Google knows and is working to know more about how entities connect and which things relate and how these relations should be valued.
Section 32: Here we read, “… the search system may place the highest weight on the prize metric for entities associated with the “Film” domain and may place the highest weight on a contribution metric for entities associated with the “Book” domain.”
Again a fairly simple premise both worth noting in this post. Prizes are valued based on the entity they are referencing. An Oscar for “The Da Vinci Code” would weight for an entity referencing the movie far more than an entity referencing the book.
One of the metrics referenced in the figures (see Figure 2 below) but not in the patent prior to section 28 is the related entity metric. Obviously determining the relatedness of an entity to a query is of paramount importance.
Section 38: As we read section 38 it’s important to understand that relatedness serves two functions here. The first is to determine whether the entity is to be ranked related to the query and the second is to determine the relatedness between two entities to pass value and weight between them. This may seem a bit confusing but let’s read the section first and then get into it:
“In some implementations, the search system determines a relatedness metric by identifying an entity reference and a related entity reference. For example, the frequency with which two words or blocks of text appear near on another in a collection of webpages may be used to determine a relatedness metric R. In some implementations, the entity reference is associated with a received search query. In some implementations, the entity reference and the related entity reference are included in a data structure …”
They go on to state, “In some implementations, the search system determines a related entity reference metric based on the co-occurrence of the entity reference and the related entity reference among webpages … In some implementations, the relatedness metric R is equal to the co-occurrence. In some implementations, the search system may scale, normalize, weight, combine with other data, or otherwise adjust a co-occurrence to determine a relatedness metric R.”
So what we’re really seeing here is the use of relatedness to connect words within a page to establish whether they are related. We saw this previously in Section 17 but the figure provided puts this as the first metric to be factored in and that is worth noting.
The patent goes on to illustrate some examples of how metrics can be measured. As they are fairly self-explanatory but quite telling, I will simply list them here with a short breakdown after:
- Section 43: “… rankings are based on popularity, relevance, frequency, user selections of entities and data associated with entities, system settings, predetermined parameters, any other suitable information, or any combination thereof.”
- Section 44: ” In some implementations, objective contribution metric C includes information related to an entity reference’s popularity, performance, relevance, importance, quality, any other suitable characterization, or any combination thereof. For example, a restaurant may be rated by a newspaper reviewer on a scale of 0 to 3 stars.”
- Section 45: “… rankings are combined based on the number of reviews, the popularity of the particular website, predetermined parameters, system settings, any other suitable parameter, or any combination thereof.” and “… the search system may combine professional critic reviews and user reviews of restaurants, giving more weight to the professional reviews and less weight to the user reviews.”
To me some of the key takeaways of these three sections is that user selection is a metric (good to see CTR confirmed again as a metric), that not all reviews and external signals are weighted the same. My review on Yelp will hold a lot less weight than that of a review in the New York Times and that the review and external metrics can and likely will be combined with values assigned based on the entity-type and a final score generated.
Before moving on it will be helpful to see Figure 4:
Nodes:
- 406
- 402
- 404
- 408
Edges:
- 412
- 410
- 418
- 416
- 414
- 420
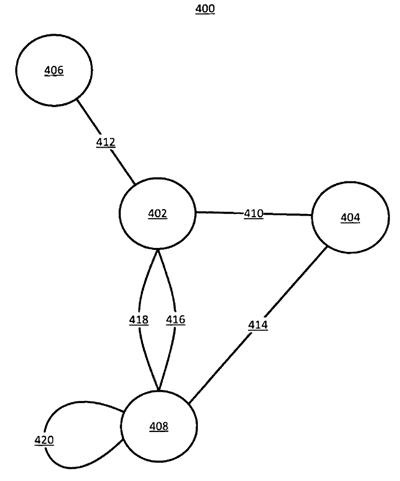
Section 59: In section 59 we read, “The nodes each contain a piece or pieces of data and the edges represent relationships between the data contained in the nodes that the edges connect.” What they are stating here is that the nodes are data points themselves and the edges (the lines in the diagram) are the relationship between them. In many cases the nodes will be entities themselves as becomes clear in …
Section 61: The possible information represented by a node as outlined in the patent is, “Nodes may represent entities, organizational data such as entity types and properties, literal values, and models of relationships between other nodes.” For example, Node 402 could be “Dave Davies” with me as the entity. Node 406 could be “SEO” with the edge 412 being the relationship “occupation”. Node 404 could be “6 ft. 4 in.” with Edge 410 being the relationship “height”, and so on.
Of course, there are many Dave Davies’ in the world and I’m far from the most famous of them. Let’s consider the following image taken on my trip to Wales a couple years ago …

The query “dave davies” then has two entities in this very picture. And then of course there’s “that guy from The Kinks” who wins it for the knowledge graph. Google refers to separating us all as “differentiation”. As we know, entities need to be unique and all of us are aside from our shared name. Google outlines their method for addressing this in …
Section 68: In section 68 it reads, “In some implementations, nodes may be assigned a unique identification reference. In some implementations, the unique identification reference may be an alphanumeric string, a name, a number, a binary code, any other suitable identifier, or any combination thereof. The unique identification reference may allow the search system to assign unique references to nodes with the same or similar textual identifiers. In some implementations, the unique identifiers and other techniques are used in differentiation, disambiguation, or both.”
Essentially to Google I am not “dave davies” but rather an identifier that happens to have the Node “dave davies” tied to me by the Edge “name”. While it’s obviously important to know one “dave davies” from another, in Section 70 Google covers a perhaps more complex and important distinction to be made and that is how to treat one name is given to entity when there are possible entity types that could be being referred to. They illustrate this with the example of Philadelphia which is a movie, a city and a brand of cream cheese. Distinguishing the user intent among these completely different types of entities is arguably more complex and less forgiving than between entities of the same type.
The Takeaways
There’s obviously more to the patent but this covers the important points we need to know to move forward. Now that we know what we’re working with in the context of what’s covered in the patent itself, let’s consider what it means. Interestingly, to this point we’re at over 3,000 words (well done on making it this far). Fortunately there isn’t much farther to go and I’m going to put it in point for easy reference. Here’s what you need to know about this patent and what it tells us about entities moving forward:
- There are four core metrics that determine the value of an entity: relatedness, notability, contribution and prizes
- Elements that appear together frequently will likely be related via co-occurrance
- Through Edges, multiple nodes can be connected and relatedness established. We can take from this that a relationship an entity may have to a movie will tie it to an actor in that movie as well though to a lesser degree.
- The order of valuing an entity is Relatedness > Notability > Contribution > Prizes > Weights Factored > Score Determined. Google does allow for wide variance here and while this is the order in the patent, the weights assigned may greatly skew this.
- User selection and popularity are ranking factors for entities.
- Reviews count in ranking factors for entities.
- An entity is a marker built on nodes and edges. It is the value of those Nodes and Edges that determines the placement of that marker and so to rank an entity, it’s those that need to be focused on.
Questions?
If you have any questions about this patent I invite them in the comments below.