
Let’s start this report by answering the obvious questions you’re likely asking:
What Is Google FLAN?
FLAN stands for Finetuned LAnguage Net, and describes a method for improving zero-shot learning for Natural Language Processing (NLP) models by using natural language instructions (instruction tuning) by making use of pretraining, finetuning and prompting.This last one is specifically interesting – and the focus of the method.Here are some important links related to this article, you may find helpful.
- The Paper: Finetuned Language Models Are Zero-Shot Learners
- The GitHub Repository: https://github.com/google-research/FLAN
Let me take an aside before we continue, and answer a question some of you make have, and an understanding of which is crucial to understanding the importance of this advancement.
What Is Zero-Shot Learning?
Zero-shot learning is a machine learning term that describes the ability of a model to to be applied to a task when it has received no training on that task, but has been trained on tasks of other types.What’s important about zero-shot for our purposes is based on the inventor, namely Google.Google search results are influenced significantly by machine learning techniques concentrated mainly in the NLP space. The ability to move learnings from one task to another to speed up the progress in that new task is highly significant.More on this below.
What About Pre-Training, Fine-Tuning and Prompting?
Some other core concepts that will be helpful to understand before we proceed are:
- Pre-Training: Like humans, machines can transfer knowledge from other area of learning to another (assuming they are enables with said capacity, and I’m not just referring to the computers here). In pre-training, a model from one task is taught to recognize new parameters that may apply as well as trained on new starting weights for the parameters in common. After all, sentiment analysis is going to weight word order in a different way than translation, but the parameters involved are common to both.
- Fine-Tuning: With fine-tuning we basically take the weights of a model trained in the domain that we want to train a new but different model for, and initialize that new model with those weights. Let’s say we have a model trained in sentiment analysis and we want to train a new model for it, but it’s trained previously for reading comprehension. We would fine-tune the new model by initializing it with the weights from the previous model trained in the domain we are training ours for.
- Prompting: Prompting, in machine learning, is using a piece of text added to the statement, to turn it into something that can be answered by a system. For example, we might take the review, “He never went back to that restaurant.” and if we wanted to determine the sentiment of it, add to the text, “The food was” and let a system trained to answer that question determine the sentiment of the review.
And Now, Back To FLAN
Before we get into why FLAN is a big deal, it’s important to understand how the training of the model works, and the results.
I’ll ask readers to not just think about the literal description of the domains and tasks I’m referring to below, but also how this could be applied at a larger/different scale. For the SEOs in the crowd, think about Google – the inventor – as a massive scrapping machine, indexing everything that is, and sometimes only then thinking of ways to use what they have.
I’m about to dive into some technical details about FLAN. What it is, how it was trained, results, etc. If you’re an SEO reading this and just want to know how it might affect search, you can jump to here.
The Problem FLAN Tries To Solve
Many machine learning models can take a long time, and are very expensive to train – especially is there are no similar models trained on the task.Adding to the problem, developing training data can also be time-consuming and expensive.The dream then, is to develop models that can be trained from other domains to allow for the quick reuse of trained data, and ideally with little-or-no additional training data required for the new task.As described above, the little-to-no additional training data requirement is called zero-shot and that’s what FLAN was designed to be.Here’s a bit of teaser as to how it all plays out:
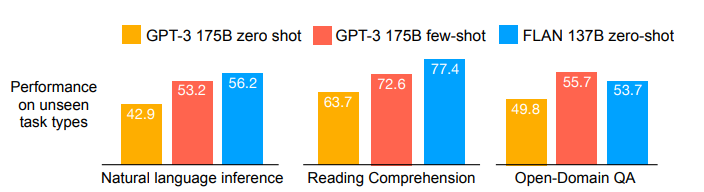
In the end, FLAN outperformed GPT-3 zero-shot models in 19 of 25 tasks.
Setting Up FLAN
Understanding how FLAN was fundamentally setup for this paper is best taken right from the paper itself:
“We take a pretrained language model of 137B parameters and perform instruction tuning—finetuning the model on a mixture of more than 60 NLP tasks expressed via natural language instructions. We refer to this resulting model as Finetuned LAnguage Net, or FLAN.”
The then setup 12 task clusters from 62 datasets (available here).
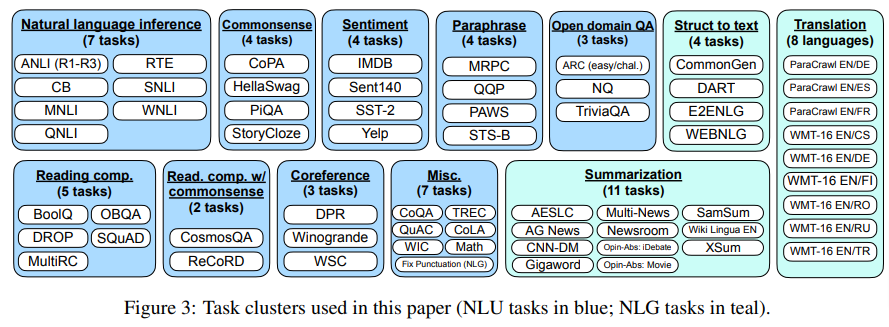
Write a caption…For each task they composed ten instruction-tune templates. An example of a instruction tune template is illustrated in the paper:
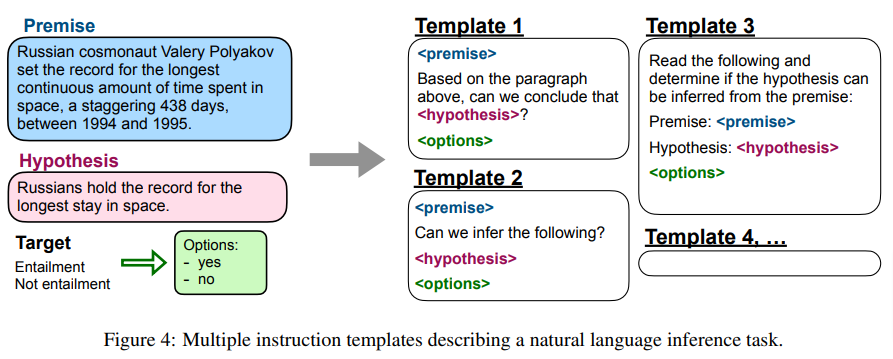
Write a caption…Of the ten template, 7 followed the core premise of the task (i.e. take 7 reviews and determine which are positive and which are negative) and 3 “turned the task around” and they system was tasked with (for example) creating a negative review.A good example of how this is done via natural language instruction is illustrated in the paper with:
“As noted by Brown et al. (2020), perhaps one reason why GPT-3 struggles with NLI is that NLI examples are unlikely to have appeared naturally in an unsupervised training set and are thus awkwardly phrased as a continuation of a sentence. For FLAN on the other hand, we phrase NLI as the more natural question “Does <premise> mean that <hypothesis>?” and achieve much higher performance.”
Technical Training Details
The experiments used a transfromer language model with 137B parameters.About 90% of the pretraining data was English (good to know your bias).The dataset they were working with was not as clean at the GTP-3 training set, and thus they were expecting zero-shot and few-shot performance to suffer slightly.The instruction-tuning pipeline mixed the datasets and randomly sampled examples from each. As the training data numbers differed significantly (translation, for example, had far more than others) they limited the number of training examples used to 30,000.
Note: parts of this section get a bit over my head, and I invite you to read page 4 of the paper linked to above for additional details if desired.
Results? A Good FLAN
In short, FLAN beat GTP-3 in 19 or 25 zero-shot tasks.Here’s how that broke down.
Natural Language Inference
In these tasks the model is given a premise and a hypothesis and must determine whether the hypothesis is true or not.Here are the results:
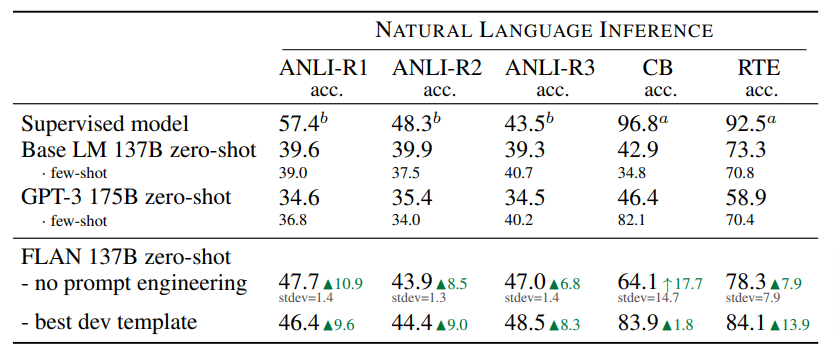
Write a caption…FLAN was strong across all NLI tasks, not just outperforming GTP-3 zero-shot, but also GTP-3 few-shot and remarkably, even supervised BERT on one.
Reading Comprehension & Open Domain QA
For reading comprehension, models are asked to answer a question based on provided information.Results:
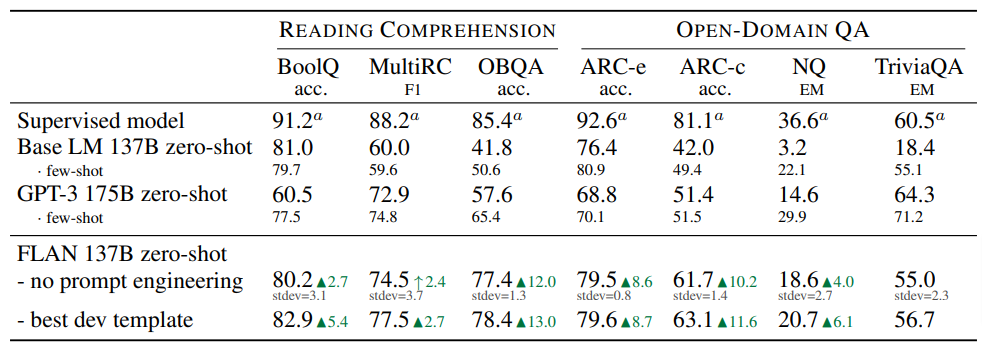
Write a caption…Once more, FLAN beats even few-shot GPT-3 in most tasks.
Commonsense Reasoning & Coreference Resolution
With commonsense reasoning, models are asked to make presumptions on the types of situations we all face every day.
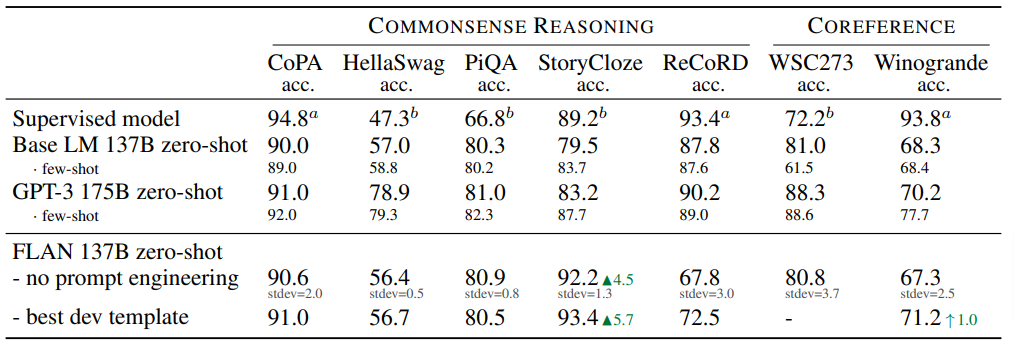
Write a caption…As we can see, FLAN does not excel in these types of tasks.
Translation
Translation I don’t think needs an explanation. And if it does, this should do it:
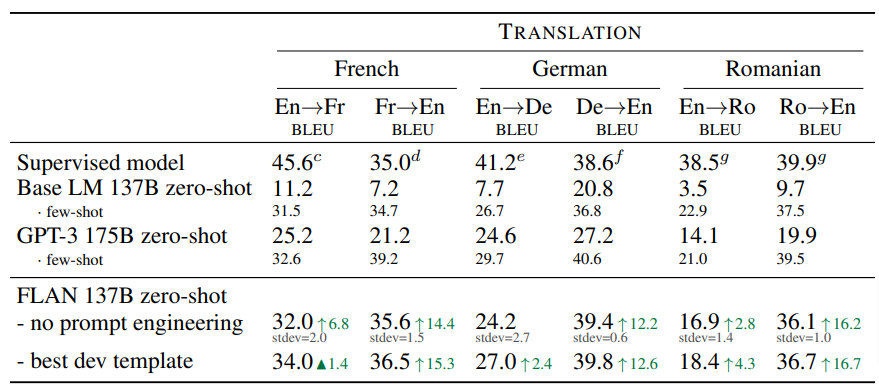
Write a caption…FLAN out-performs zero-shot GPT-3 in all case, but not few-shot.
Ablation Studies
Let’s begin with the first question I had:
What is An Ablation Study?
An ablation study in machine learning is quite simply the removal of specific elements of the experiment (a feature, for example) and re-running the model to better understand that element’s contribution to the result.
The FLAN Ablation Studies
The first study they performed was holding out NLI, open-domain QA, and commonsense reasoning as evaluation clusters, and used the seven remaining clusters for instruction-tuning. The results were:
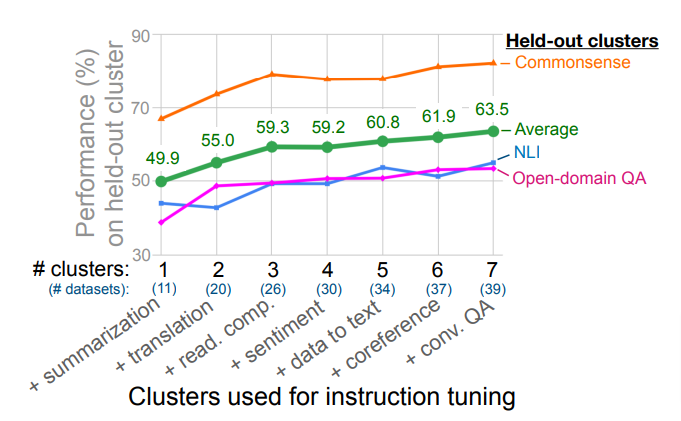
Write a caption…The performance continued to improve as clusters were added with no sign of that stopping. More clusters, it seems, would contributed to stronger and stronger models.
Scaling Laws
The second ablation study they performed was in data scaling, that is, testing performance improvement on increasing model sizes.The results there were:
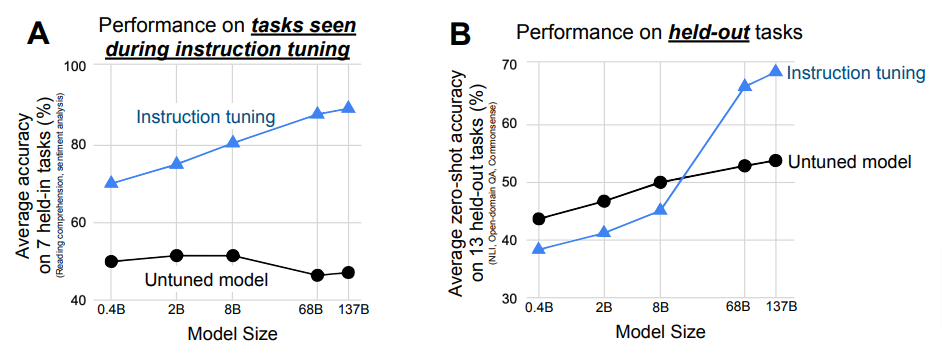
What we’re seeing here is that the model size impacts both scenario (there they tasks being performed are seen during instruction tuning, and where they are not) BUT what’s interesting in that untuned models actually perform better than tuned models for smalled model sized when asked to perform in the held-out tasks.This makes sense when we think about it. When the model is tuned on a task, it will naturally do better at that task however when you have a model trained on one task, it will take it a bit to apply what it has learned to a new task.You can teach an old model new tricks, you just need to give it a minute to figure the trick out.
FLAN And It’s Impact On SEO
While the research behind this paper is different than reading a piece on MUM (for example) the impact is significant.Think for a moment about a Googley system that can learn from one domain, and use that skill to dramatically increase its accuracy in another.Imagine taking what they know of news (a high volume domain to be sure), and using that to learn how to better understand the sentiment of your review of a restaurant.Imagine Google being able to take skills it learns in translation, and using them in unrelated tasks to help manage your house via Google Assistant.And truly, these are probably horrible example.The power behind methods like this is vast. The ability to more reliably and efficiently transfer learnings from one domain to another, with little additional training required is how these systems will make massive leaps forward in the coming years.So, as an SEO will this impact you directly? Probably not, unless you consider almost constant algorithmic updates, and a vastly improved understanding of the world and your website’s place in it direct.The models and methods outlined in the paper are works in progress. I suspect we’re at least a year out from the deployment of these types of systems into a significant part of Google.That said, I may easily underestimate the speed they’re progressing.
Credits
Some resources I found helpful in the writing of this piece: