
You may not have heard of ByT5, and until a couple weeks ago (May 28, 2021 to be exact) no one outside Google had.
On the 28th, Google AI published a paper (you can find it here) on a new NLP model called ByT5.
I don’t read every paper they put out obviously, but this one really caught my eye. The title of the paper is, “ByT5: Towards a token-free future with pre-trained byte-to-byte models”. It’s the “token-free” that drew me in.
Before we dive in, what will be be covering?
Sections We’ll Be Covering
- What Is A Token In Machine Learning?
- What Is ByT5?
- Tokens vs Token-Free: The mT5 vs ByT5 Research
- The Pros And Cons Of ByT5
- The Results
- Why ByT5 Matters For SEO
Let’s dive in …
What Is A Token In Machine Learning?
A token in Natural Language Processing is a representation of a word, word segment (subword) or character. When text is being processed, a tokenizer breaks that text into tokens, so those tokens can be processed by the system with historically higher efficiency that processing the same text character-by-character.
For example, the sentence:
The quick brown fox.
Would be 6 tokens in a tokenized world. One to begin the sentence, one token for each word, and a token to end it.
Some words require multiple tokens. For example the word “playing” might have one token for “play” and one for “ing” as “ing” has a unique meaning in NLP, and this also keeps the number of tokens needed for a language under control.
At the byte level however, we have 20 “tokens” in the same sentence.
To give you an idea of how token length impacts what can be done, in models like BERT, tokens have an upper limit of 512 to be processed at once before the compute costs becomes too high to be functional.
With just this information it’s fairly easy to see how tokens make sense, how they dramatically reduce the computing power required to run, and basically – why they’re used in most NLP tasks.
But what it ByT5 and why is it different?
What Is ByT5?
ByT5 is a byte-to-byte token-free text-to-text transformer model. Basically, it doesn’t use tokens and is designed to process unilingual and multilingual NLP tasks.
One advantage to token-free models is that they are historically more resistant to noise than token-based models. More on that below, and why that’s important for what this means to SEO.
And additional advantage that the authors discuss is the challenge that, “… there is no obvious way to process a piece of text that contains an out-of-vocabulary word. A standard approach is to map all unknown words to the same <UNK> token, which prevents the model from distinguishing between different out-of-vocabulary words.”
<UNK> in simply “Unknown” and one can see that it is not particularly helpful in a variety of situations.
This issue exists in English-to-English translation as much as in multilingual tasks such as translation to-and-from little-known languages.
Take for example a system designed to understand English vocabulary, analyzing a gaming site, and hitting the statement, “He got pwned”.
To a token-based system this would become:
[CLS]-[He]-[Got]-[UNK]-[SEP]Or possibly:
[CLS]-[He]-[Got]-[UNK]-[ed]-[SEP]To a token-free system it becomes:
[H]-[e]-[ ]-[g]-[o]-[t]-[ ]-[p]-[w]-[n]-[e]-[d]Which system do you think would be more likely to figure out what was intended?
Tokens vs Token-Free: The mT5 vs ByT5 Research
Note: in this section we’re outlining the study and how it was conducted and my attempt at why. It is not necessary for SEO-specifically, and can be skipped if you just want to just to what it means.
Click here to jump right to the part about SEO impact.
The authors of the paper pitted the token-based mT5 model (also from Google) with the token-free ByT5.
By Google’s own words, “mT5 achieves state-of-the-art performance on many cross-lingual NLP tasks, as of November 2020.”
So a good test.
How Tokens Are Used
An illustration of what I was trying to get across with the pwned example above, is given in the paper with:
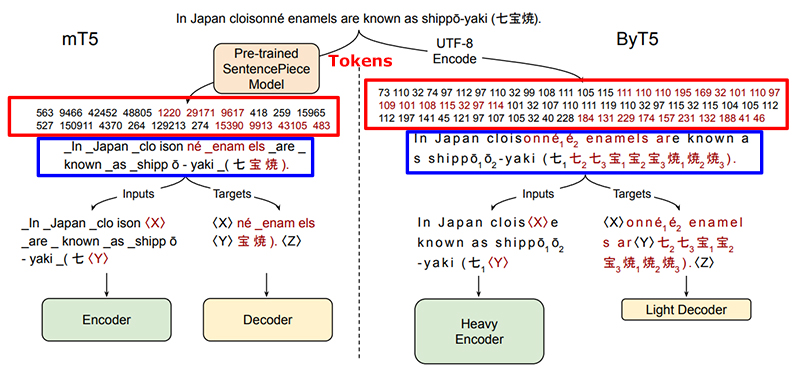
If you don’t see what’s going on right away that’s OK. You shouldn’t unless you really know Machine Learning and tokenizers. I had to read the process in the paper to really understand what was being displayed, but it’s good to have the image already available to you for reference (as it was in the paper).
One of the first things you might notice is how much shorter the mT5 tokens are than the ByT5 (in the red box). This is because every character is treated as a token, as opposed to words and/or word segments being used whenever possible by token-based systems.
In the blue box you see an example of how the training works. It’s similar in most (all?) NLP training models I’ve seen (not that many 😉 ).
So the system is programmed to remove X number of tokens out of every Y number. In each of the examples given, there are two sets of tokens removed, and replaced with a placeholder (<X> and <Y> in the example above) for use in training
The encoder of the system is given the content with the sets of tokens missing and the placeholder to understand where the missing tokens are located.
The decoder is given the removed tokens, with the related placeholder assigned in location of the content that is hidden to it. Essentially, one part of the system knows the content but is missing a few tokens, and the other part knows only the missing tokens (answer).
Through training, success is measured by how reliably the model can “guess” which option sent to it from the system when it is given input from the encoder, is right. So if we say a model has 80% validation, that means that out of every five segments sent to it from the encoder, it was able to match the corresponding result from the decoder four times.
The Technical Architecture

This section I’ll be mainly copying and pasting what is written in the paper, with a brief explanation beneath each quote.
“We release ByT5 in five sizes analogous to T5 and mT5 (Small, Base, Large, XL, XXL). We aim for ByT5 to cover the same use cases as mT5: it is a general-purpose pre-trained text-to-text model covering 100+ languages. We expect ByT5 will be particular useful for tasks operating on short-to-medium length text sequences (a few sentences or less), as these will incur less slowdown in fine-tuning and inference.”
In this section we see that they are giving it five sizes of content to work with (size being determined by the number of parameters), covering over 100 languages. The prediction is that ByT5 will be better at shorter text.
By “better”, part of what we need to keep in mind is the compute cost. How long and how much energy does it take to train the model, and produce a result. After all, a marginally better system, that takes 100x longer to run would generally not be considered successful. With the ~5x more tokens required for the same text, ByT5 would likely get bogged down at larger scales.
Aside: Before we think this might render it useless, remember that BERT taps out at 512 tokens, and SMITH at 2,248 and yet BERT is still around, still doing some jobs better than SMITH ever could.
To continue …
“Second, we modify the pre-training task. mT5 uses the “span corruption” pre-training objective first proposed by Raffel et al. (2020) where spans of tokens in unlabeled text data are replaced with a single “sentinel” ID and the model must fill in the missing spans. Rather than adding 100 new tokens for the sentinels, we find it sufficient to reuse the final 100 byte IDs. While mT5 uses an average span length of 3 subword tokens, we find that masking longer byte-spans is valuable.”
What we’re reading about here is what I was trying to explain above with the replaced tokens in the illustration. In mT5 they replaced (masked) 3 tokens. The authors here wanted to mask more tokens, I’m gathering because masking 3 bytes would not be effective in training a good model for most tasks. Like starting a 100 piece puzzle with only 3 pieces missing.
“Third, we find that ByT5 performs best when we decouple the depth of the encoder and decoder transformer stacks. While T5 and mT5 used “balanced” architectures, we find byte-level models benefit significantly from a “heavier” encoder. Specifically, we set our encoder depth to 3 times that of the decoder.”
This I found interesting, though mainly because I had never thought to even consider the relationship between the number of encoders and decoders. mT5 used balances architectures (same number of encoders and decoders) but was tested with different number in this research, as was ByT5.
The Pros And Cons Of ByT5
The authors were very clear on the pros-and-cons of ByT5. Like they were real scientists looking for answers, not just to pad their resumes with another paper.
(though who knows, maybe it only sounded that way based on the results we’re getting to shortly 😉 )
Some of the pros-and-cons listed
Pros
- Large vocabularies (e.g. those in multilingual models like mT5), the vocabulary matrix can make up a substantial proportion of the model’s parameters. Sometimes about 66% of the total parameter count. Switching to a byte-level model therefore allows allocating these parameters elsewhere in the model, e.g. by adding layers or making existing layers “wider”.
- Likely ability to handle noise more effectively.
Cons
- Changing from a word or subword-level token sequences to byte sequences will tend to increase the (tokenized) sequence length of a given piece of text and byte-sequences can results in a significantly higher computational cost.
- For byte-level encoder-decoder models, if the decoder is particularly large, autoregressive sampling can become comparatively expensive thanks to the longer sequence lengths of byte sequences. Relatedly, mapping an input token to its corresponding vector representation in the vocabulary matrix is essentially “free” in terms of FLOPs since it can be implemented by addressing a particular row in memory. Therefore, reallocating parameters from the vocabulary matrix to the rest of the model will typically result in a model that requires more FLOPs to process a given input sequence
The Results
Finally we get to the results. The only thing standing between us, and the conclusion of what it means for SEO.
They summarize the core results as:
“ByT5 is competitive with mT5 on standard English and multilingual NLP benchmarks and outperforms mT5 at small model sizes. Additionally ByT5 excels on free-form generation tasks and transliteration.”
Using two industry benchmarks in natural language understanding systems (GLUE and SuperGLUE – yes, those are actually the names) ByT5 outperforms mT5 on small and base model sizes by sizable margins, and loses close battles on larger models.
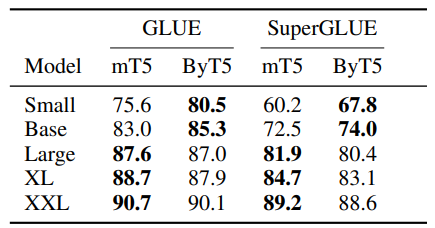
What I found fascinating as an SEO was how it performed on XSum asbtractive summarization tasks and TweetQA. XSum gets the model to summarize a news article in a single sentence, and TweetQA is question answering from Tweets. Basically, two very real world scenario with very different language use and information structure.
ByT5 crushed it:
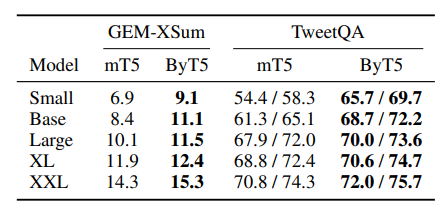
When they compared the two with six tasks:
- Two classification problems
Classification: a predictive modeling problem where a class label is predicted for a given example of input data.
Think: predicting if an email is spam. - Three extractive problems
Extractive: a summarization model where data is pulled from content and summarized by the system.
Think: featured snippets. - One structured prediction
Structured prediction: Structured prediction is a generalization of the standard paradigms of supervised learning, classification and regression. All of these can be thought of finding a function that minimizes some loss over a training set. (source)
Think: in voice search, determining the query when one of the words is noisy.
The tasks below were translation tasks.
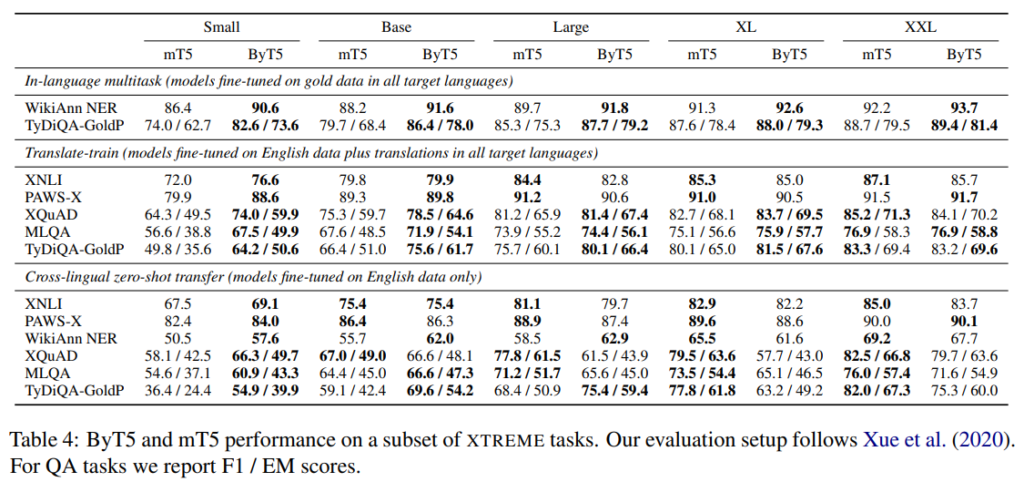
ByT5 dominates in all small and base models where gold training data is available (that is, where the system was training in English and had access to translations in training, but underperformed mT5 in all but the smaller zero-shot models, where the system was not been given translation data.
That said, it did perform well on single-word translations and ByT5 won on all size models.
Quiet !!!
Where ByT5 really shone was when noise was present.
To test this, they ran six different scenario:
- Drop: Each character has a 10% chance of being dropped.
- Add/Drop/Mutate: At each character position, there is a 10% chance of applying one of three actions, with equal likelihood: Add (inserts a random character from the input), Drop (deletes this character) or Mutate (replaces this character with a random character from the input).
- Repetitions: Each character has a 20% chance of being selected for repetition. If selected, 1–3 repetitions (with equal likelihood) are appended after the original character.
- Antspeak: Each character is capitalized and padded with spaces. For example, “abc def” becomes “ A B C D E F ”.
- Uppercase: Each character is converted to uppercase. Here, we restrict to languages whose scripts distinguish case (for XNLI: Bulgarian, English, French, German, Greek, Russian, Spanish, Swahili, Turkish, Vietnamese; for TyDiQA-GoldP: English, Finnish, Indonesian, Russian, Swahili).
- Random case: Each character is set to a random case (upper or lower). Again, only languages whose scripts distinguish case are considered.
The results?
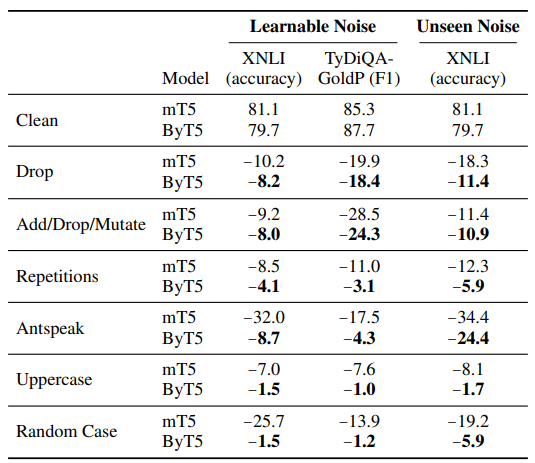
The effects were nearly identical across all languages.
Now think of how you type of social media or in text for a second, if you want to understand the power of this.
You’ll notice there’s an “unseen noise” column. For that data, the system was not trained to recognize noise (i.e. hadn’t encountered it in training). The goal of this is to, “… making models more future-proof as well as more resilient to accidental or adversarial spelling mistakes.”
As noted above, a lot of the strength of ByT5 relied on decoupling the encoder and decoders, so they did the same with mT5. mT5 improved with more encoders, but not to nearly the same degree.
They Concluded that:
“ByT5 outperforms mT5 in any of these four scenarios: (1) at model sizes under 1 billion parameters, (2) on generative tasks, (3) on multilingual tasks with in-language labels, and (4) in the presence of various types of noise.”
Additionally they note:
“… the gains we observe with ByT5 are achieved despite the fact that the model is pretrained on 4 times less text than mT5. This suggests that byte-level models could be more data efficient learners.”
This may be critical for many tasks where training sets are limited. Translation to lesser-spoken languages, for instance.
And their big conclusion …
“Our “hands-off” approach of feeding raw UTF-8 bytes directly into the transformer costs +33% pre-training time, as well as longer inference time (10–50% longer for small models, and 100–600% longer for our largest models). As such, there is significant room for improvement. We believe techniques such as hash embeddings, local attention and down-sampling (Clark et al., 2021), as well as sparse computation (Fedus et al., 2021) can help address latency issues, removing the remaining barriers to a token-free future.”
Why ByT5 Matters For SEO
Finally you made it. Or maybe you jumped right here. Either way, let’s dive in.
What’s important to really understand from an SEO-perspective here is that we have a system that, for specific tasks significantly exceed current State Of The Art.
While ByT5 takes longer to train, and underperforms in some tasks (zero-shot translation for example) the payoff for tasks where noise is an issue (think social and voice) is significant.
As SMITH is to BERT, I am not suggesting that token-free models will replace token-based. Each are good at their own tasks. What I am suggesting is that one of two things is likely to come, as related to SEO:
- Tasks that token-free models perform better on will be assigned to them, with a mechanism in place to bridge the gap between token-free and token-based systems to share information.
An example of this might be producing a search result with a news-based featured snippet or other results taken from both journals and social media. The journals would likely be handled better with token-based systems, and social media with token-free. They would then need an additional mechanism for combining this data.
The compute cost of this could be high.
I don’t view it at likely in most scenarios for the short term, but clearly more research will be done in this area. - More likely in the short term IMO is that token-free models like ByT5 will be used in the training process for token-based system.
Token-based systems tend to underperform when dealing with noise, misspellings, etc. , and aren’t as quick on tasks with fewer parameters to contend with.
So what I see happening is token-free systems being used to feed data back to model during training.
Remember, in training a segment of content is broken into tokens (in mT5, etc.) and blocks of tokens removed (masked) and sent to the decoder, with the remaining content sent to the encoder. The model then tries to determine what block if missing, which is then verified by the decoder.
It is in the gap between the system being given the data from the encoder and being given the answer from the decoder that the magic happens.
Our token-free system could collect information from noisy environments and to more quickly learn new terms being used as shorthand, and even emojis and many other similar tasks. They could then use this to trainthe token-based system to recognize these things.
Basically, their impact (assuming this is how things play out) could be felt not in direct application, but in training the token-based system how to deal with what token-free systems do better.
Where we as SEO’s will see the difference is in better answers being produced by systems like MUM.
IMO, this is a step down the long(ish) road to Google creating and presenting their own content, a collection of data based on the work of others (sorry publishers … it’s coming) and presented zero-click.
Additionally, this will likely dramatically enhance voice search technologies where noise (figurative and literal) is high.
This research needs to be advanced before deployment by my understanding, and the next steps are touched on in the paper – but this kind of research likely won’t take long. In fact, it’s probably already underway.
And with each new Google Core Update you can wonder … is this what they’re introducing?