
It’s been a month since Google introduced the SEO community to BERT. This isn’t to say that that’s when it first started impacting queries, but that’s when we heard about it.
They have since told us that it can’t be optimized for.
Well … before we dive into what you can do to optimize for a system that Google tells us can’t be optimized for, let’s first take a look at what BERT actually is.
What Is BERT: Cutting Through The Crap
There have been a lot of articles and posts written about BERT. Some were very insightful but others were just rubbish. As Ryan Jones so eloquently pointed out:
the most exciting thing about BERT is that suddenly, overnight, every SEO is now an expert on neural networks and natural language processing.
— Ryan Jones (@RyanJones) October 25, 2019
Now let me be the very first to note, I am in no way an expert in neural networks nor Natural Language Processing.
I do however, take the time to read a lot of technical documents, including the documents outlining how BERT was trained. A bit dry to be sure, but brilliant.
So take what follows in that context. There are people who know more than I about the mechanics but I like to think I know how it impacts SEO a bit more than they might.
I’ll list some other articles I find to be great reading on the topic at the end of this post. They’re highly recommended.
So let’s cut to the chase …
What Is BERT?

BERT is a fundamental change in how natural language processing works.
It stands for Bidirectional Encoder Representations from Transformers.
It’s the B that is at the heart of the breakthrough that makes it state-of-the-art, but as we will get into and as Rani Horev importantly points out, it is more accurately considered non-directional than bidirectional. His article is linked to below.
Let’s consider the fundamental issue with natural language processing. The methods used to this point (and even in many implementations and tasks still in use for that matter) operate from left to right or right to left. That is to say, they only understand one thing based on what has been encountered before it. For our purposes here we will consider the left-to-right structure given that it’s how you’re reading this article.
If we take for example the sentences:
When Dave looked across the room he got mad. Trevor was eating his ice cream and he didn’t like it.
When the system hits the word “his” in the second sentence it will have a choice between Dave and Trevor as to who that refers to. When it then hits the word “he” it will hit the same options. Using non-BERT Natural Language Processing (NLP) systems (ELMo for example) it assigns probabilities to these values as to their level of likelihood in being correct. The systems worked pretty well, they were accurate up to 75.1% of the time.
Not bad right? Until you imagine a world where you only understood the context of a sentence 75.1% of the time.
Enter BERT…
With BERT, the system takes in all the sentence elements simultaneously. It is illustrated as:
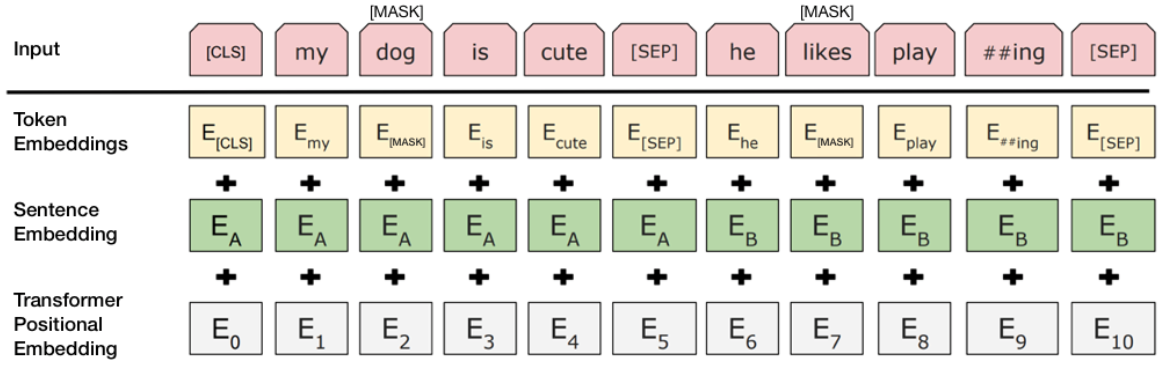
This doesn’t illustrate it perfectly and covers more than we’re discussing right now but what we’re considering is that each of these elements is viewed independently rather than being reliant on what came before it. This is not to say that positional context is not considered, but often to the contrary – becomes more emphasized. If the context of a word is made clearer by what comes after it, or by words both before and after it, this is now understood where previously is was not.
The input element “dog” for example, is known to be located one position to the right of “my”. This would produce the connection “my dog” or “the dog who belongs to me”.
But instead of relying on position, the system takes advantage of the full range of neural matching, including a far stronger capacity to consider an element’s various meanings and definitions in isolation, then take that information into the context of its position relative to other elements.
When we think about this from a single statement as shown above it we can imagine many glaring holes the system would encounter in building a model to predict how language is arranged on a new phrase.
That’s why BERT was trained with the BooksCorpus and English Wikipedia giving it a total of over 3 billion words, formed into sentences of various reading levels, meanings and contexts.
The REALLY Interesting Parts
The really interesting parts (to me at least) are:
The use of masks (illustrated above with “dog” and “likes”) to hide words from the system during training (this also exists in previous NLP systems). As part of the training the system is then tasked with predicting what the masked word is.
We won’t get into this further as that’s getting into machine learning training, but it is the first of the unsupervised learning tasks that make up the model. Predicting words that would likely be in a sentence based on the context of what’s around it.
The second is arguably even more interesting and is critical to our understanding of how we need to think about BERT and how to optimize for it. And that is the training that takes place with sentences.
BERT is trained by giving it a sentence as the first sentence. It is then given two additional sentences, one that is the next sentence in the sequence, and one that is a different sentence from the same document but not the next sentence.
The system is then tasked with learning to accurately predict which sentence comes after the first sentence using the non-directional understanding of how words order, and what words represent.
To me at least, this is a brilliant method. So brilliant do I think it is, as I was reading the documentation and taking notes I wrote in the margin:

Yes … apparently a revolution in natural language processing is, in this layperson’s opinion, “smart”. Just a titch of an understatement.
So What Did This Get Us?
I have to remind you, I am no expert and I highly recommend reading the docs linked to throughout this post and below to gain a far better understanding of BERT and NLP than I could present if this is of interest. But I hope it sets the stage for what we as SEOs can do to impact rankings.
Remember that previous techniques got us 75.1% efficiency. BERT scored an 82.1%. This is a whopping 9.3% improvement.
Thinking About BERT As An SEO
One of the first things that struck me when BERT was first announced was that it’s not really a ranking factor. It’s a filter.
In the example they gave in the announcement, Google illustrated a query it impacts with:
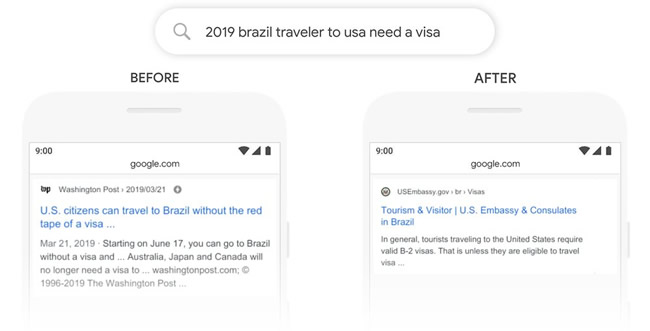
Basically, the new system understands the direction of the traveler and is not actually giving a boost to the sites that fit that, but rather filtering out or devaluing sites that do not.
Yes, this may seem like semantics and yes I may sound like a Googler, BUT it’s an important difference and is what leads Google to the accurate statement:
There’s nothing to optimize for with BERT, nor anything for anyone to be rethinking. The fundamentals of us seeking to reward great content remain unchanged.
— Danny Sullivan (@dannysullivan) October 28, 2019
You can’t optimize for BERT, so …
Here’s How To Optimize For BERT
Remember: Optimizing for BERT is optimizing for a filter, not an algorithm.
The difference is substantial. In the case where we find ourselves optimizing for a filter, the goal is not to optimize but to clarify.
Let’s look at the example above, we want to rank for a query related to citizens of the Brazil wondering if they need a visa to visit the US. The question we need to ask ourselves is: how do we clarify our content?
I would:
- Have breadcrumbs that clarify that the section of the site is about Visas in the US
- Include schema on the page clarifying the location of visa offices
- Carefully ensure that easily understood connector words are use to clarity the direction. I would use phrases like: “Visa Information For Brazilians Travelling To The US”
- Consider what other topics and entities will exist on a page that clarifies that it is Brazilians looking for via information and not Americans traveling to Brazil. This could range from information on destinations within the US, etc.
Essentially, we need to consider everything that might differentiate our content from content related to queries that use the same or similar terms. Remember, these can often be exactly the opposite of what you’re trying to rank for.
We also need to consider that there are many applications for BERT. We looked at the pre-training above but that’s for the global system. BERT is then fine tuned for specific tasks.
So consider where you’re trying to rank and cater to that. If you are trying to answer a question to appear in the featured snippets or produce the voice result you’ll want to remember the method they use for connecting and predicting which sentence follows another.
Your takeaway there is pretty obvious – if you have a question and answer, structure it such that it’s very clear to the reader (and BERT) which is which, and that each statement can operate as a standalone.
For example:
Question – How do you optimize for BERT?
Answer – While you can’t optimize for BERT, you can make your content clear in its purpose and avoid potentially confusing a system that which state-of-the-art, is still only 82.1% accurate.
And if you check the page, I’ve added the FAQ schema as well, just to make sure.
So Can You Optimize For BERT?
I would argue that you can, as much as you can for anything else.
No, there isn’t a specific metric you can use to measure for it, but you can work to make sure your words, entities and structures support a clear understanding of your content and more importantly here, context.
And I’d sure consider that optimizing.
Recommended Reading
I promised to include some additional resources that I found educational. Some of the best articles on the subject are:
- Paper Dissected: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” Explained (link no longer available)
- BERT Explained: What You Need to Know About Google’s New Algorithm
- BERT Explained: State of the art language model for NLP