As I mentioned in my podcast on the 19th of December, where Jim and I were joined by SEO patent nerds – David Harry and Bill Slawski, if I see a patent with the word “entity” in it, that’s my trigger. I gotta read it.
In fact, as I was chatting with them both I had the printed, highlighted and noted copy of my most recent read, sitting before me on my desk – waiting for the time I’d write this post.
That was 5 weeks and a holiday season ago. But here we are, ready to write up a summary of a pretty interesting patent. But first …
Why Read Patents?
If you’re interested in Google patents, what they may mean, and why you should pay attention to them, you may want to listen to the Webcology episode referenced above. Bill and David come on after the first break at the 20 minute mark:
Listen to “Blocking Googlebot-News And Bing & Yahoo Rankings” on Spreaker.
In short, they can give you insight into what’s going on and how it’s happening. Just be sure to consider the date it was filed and not when it was published. Also, it’s important to remember that not all patents are used, not all part of patents that are used are followed in full, and some are just part of other initiatives.
Nonetheless, reading them or reading evaluations of them, can yield a far deeper understanding of the why and how of algorithm updates, layout changes, and the future of tech.
So let’s dive in …
What Google Patent Are We Looking At?
The patent we’ll be looking at today is patent 20190370326, Answering Entity-Seeking Queries.
As noted above, with the word “entity” in the title, I had no choice but to read it.
Basically, what the patent outlines is a system by which Google can take in a query (including by voice) and using a dependency tree based on the entities within and specific valuation metrics, answer the question being asked.
This may sound simple enough (or not). The fact is, there are a lot of oddities in language and also a lot of ambiguous requests we send the engines every day. The systems outlined make sense and rely on multiple databases and processes to comprehend queries that you or I may view as obvious.
A Nod To BERT
This patent has nothing to do with BERT, though being filed on May 29, 2018 and remembering that they open-sourced BERT just a few months later, I don’t think is a total coincidence. Google was (and is) clearly working very hard in areas around understanding natural language.
This patent, while not directly connected, does have some overlapping ideas in their outlining of how entities are pulled from statements for processing. While this patent doesn’t discuss anything related to bidirectional evaluation, the areas discussed will be bidirectional in their benefit. BERT would make these systems better, and vice-versa.
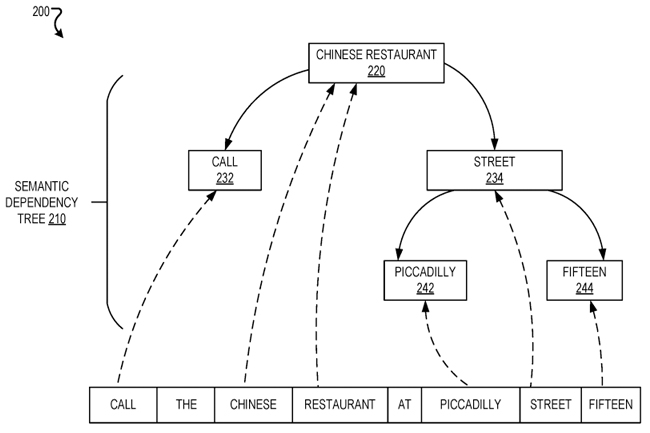
For those “skilled in the art” (inside nerd joke there for the patent readers in the crowd) you can see how this is, with a simple glancing at figure two from the patent:
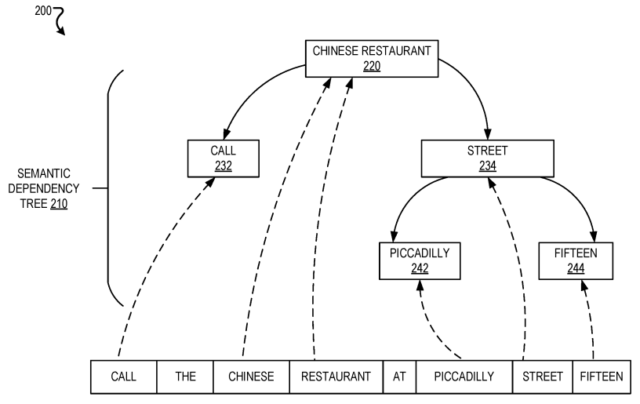
What’s displayed here, though is unidirectional however. i.e. Not BERT.
Alright, so let’s get to it. If you want to follow along, you can download the patent at the link above. This will give you a more complete view of what’s going on, but below I’ll endeavor to focus on the key takeaways and supporting ideas.
The Patent: Section By Section
To keep things fairly easy to read and reference, I’ll simply list each of the sections I found compelling and discuss what’s contained within.
ABSTRACT
In some implementations, a query that includes a sequence of terms is obtained, the query is mapped, based on the sequence of the terms, to a dependency tree that represents dependencies among the terms in the query, an entity type that corresponds to an entity sought by the query is determined based on a term represented by a root of the dependency tree, a particular entity is identified based on both the entity type and a relevance of the entity to the terms in the query, and a response to the query is provided based on the particular entity that is identified
In the abstract we see the core method outlined in the patent, summarized. Essentially, the mapping of a sequence of entities to a dependency tree. This tree, and how the entities are further classified through and in it, makes up a new method for interpreting and evaluating a query type and generating different answers based on how the query is interpreted.
Sections 0005 and 0006
[0005] The system may perform particular actions for queries that seek one or more entities. An action the system may perform may include identifying one or more types of entities that a query is seeking, and determining whether the query is seeking one specific entity or potentially multiple entities. For example, the system may determine that a query of “What is the hotel that looks like a sail” seeks a single entity that is a hotel. In another example, the system may determine that a query “What restaurants nearby serve omelets” seeks potentially multiple entities that are restaurants. [0006] An additional or alternative action the system may perform may include finding a most relevant entity or entities of the identified one or more to take types, and presenting what is identified to the user if sufficiently relevant to the query. For example, the system may identify that the Burj Al Arab Jumeirah is an entity that is a hotel and is sufficiently relevant to the terms “looks like a sail,” and, in response, audibly output synthesized speech of “Burj Al Arab Jumeirah.”
In these section we see a portion of the purpose of the patent outlined, that the system collects entities and through processing them in specific ways (through a dependency tree) to understand the meaning behind non-explicit natural language queries, yielding an understanding that the hotel that “looks like a sail” is:

We will see further below a bit on how this is accomplished. More important for this patent however is the mathematics and probabilities. Until AI takes over from ML, this is critical.
Section 0008
Still another additional or alternative action may include identifying subqueries of a query which are entity-seeking, using the above actions to answer the subquery, and then replacing the subqueries by their answers in the original query in order to obtain a partially resolved query which can be executed. For example, the system may receive a query of “Call the hotel that looks like a sail,” determine that “the hotel that looks like a sail” is a subquery that seeks an entity, determine an answer to the subquery is “Burj Al Arab Jumeirah,” in response replace “the hotel that look like a sail” in the query with “The Burj Al Arab Jumeirah” to obtain a partially resolved query of “Call the Burj Al Arab Jumeirah,” and then execute the partially resolved query.
This is fascinating.
What we see in this section is one of the critical elements of the patent outlined. When we think about how a complex search system should work this is obvious, but it’s very interesting to see it described.
Basically we’re reading clarification of the process of an action being requested where an initial query has to be conducted by the search system, to formulate the question being asked.
The query asked in the example was:
“Call the hotel that looks like a sail.”
The system, after breaking the query down into entities it would realize that there is no hotel named, “that looks like a sail”.
The system would then need to run the query to determine if there is a hotel with the attribute “looks like a sail” and that there is a high probability that their conclusion is correct.
Assuming there is, they are then changing the query to, “Call the Burj Al Arab Jumeirah” and satisfying that one rather than the user-generated query.
Writers Note: based on past patents I presume, though it is not mentioned in this patent specifically, that a supplemental database houses common secondary queries so the system does not need to actually process whether there is a hotel that looks like a sail each time, and would rather reference the database, pull the result, and move on.
Section 0009
Another additional or alternative action may include identifying that a user is seeking entities and adapting how the system resolve queries accordingly. For example, the system may determine that sixty percent of the previous five queries that a user issued in the past two minutes sought entities and, in response, determine that a next query that a user provides is more likely a query that seeks an entity as an answer and process the query accordingly.
In this section we read a subtle but important aspect of the process.
That if a user repeatedly is searching for information on a specific entity, Robert Downey Jr. for example, that if the final query was, “call him” the system would assume the entity to be called was that entity and …

Section 0015
… determining an entity type that corresponds to an entity sought by the query based on a term represented by a root of the dependency tree includes identifying a node in the tree that represents a term that represents a type of entity and includes a direct child that represents a term that indicates an action to perform. In some aspects, identifying a node in the tree that represents a term that represents a type of entity and includes a direct child that represents a term that indicates an action to perform includes determining that the root represents a term that represents a type of entity and includes a direct child that represents a term that indicates an action, and in response to determining that the root represents a term that represents and type of entity and includes a direct child that represents a term that indicates an action, identifying the root.
In this section we see a couple things of interest.
The first is that we are informed that the dependency tree will be sought for a node that implies the type of entity. For example, a query for an ambiguous term like “sponge” leaves room for confusion. Is it the animal or cleaning product?
If the query is “dish sponge” however, the node “dish” is used to identify the type of entity of “sponge”
We also see the action (if present) used to identify the same. So in the query for “buy sponge” the word “buy” could be used to identify that there is a higher probability the user is interested in a cleaning product than a sea animal.
Section 0016
… identifying a particular entity based on both the entity type and a relevance of the entity to the terms in the query includes determining a relevance threshold based on the entity type, determining a relevance score of the particular entity based on the query satisfies the relevance threshold, and, in response to determining the relevance score of the particular entity based on the query satisfies the relevance threshold, identifying the particular entity. In certain aspects, identifying a particular entity based on both the entity type and a relevance of the entity to the terms in the query includes identifying the particular entity and another entity based on a determination from the dependency tree that the query is not exclusively seeking a single entity. In some aspects, identifying a particular entity based on both the entity type and a relevance of the entity to the terms in the query includes requesting additional input in response to a determination that multiple entities are relevant to the query and are of the entity type and that the query is exclusively seeking a single entity.
In this section we see probability introduced as type-specific (i.e. there may be a different threshold for hotels than cleaning products). Further, we see additional information requested from a user to reduce ambiguity (ex – are you looking for a hotel?).
Section 0017
… determining that an amount of queries received that sought an entity satisfy a threshold and in response to determining that an amount of queries received that sought an entity satisfy a threshold, entering an answer seeking mode that resolves queries in favor of seeking an entity. In certain aspects, the dependency tree is a semantic dependency tree. In some aspects, the dependency tree is a syntactic dependency tree.
Perhaps my favorite part …
In this section we see past query satisfaction, as an indicator to reinforce entity probability assignment.
Basically … user metrics impacting rankings.
Figure 2
We’ll reference this below.
Section 0027
Re: Figure 2
A semantic dependency tree for a query may be a graph that includes nodes, that each represent one or more terms in a query, and directed edges between the nodes. A directed edge that originates from a first node and ends at a second node may indicate that the one or more terms represented by the first node are modified by the one or more terms represented by the second node. A node at which an edge ends may be considered a child of a node from which the edge originates. A root of a semantic dependency tree may be a node that represents one or more terms that do not modify other terms in a query and are modified by other terms in the query. A semantic dependency tree may only include a single root.
In this section we see outlined some of the core processes of the system, including that there can be only one root node (that is – one core entity that everything else relates to). In the example above, “chinese restaurant” is the root in that it is what is being sought, everything else is an action or clarifying node to assist the system in understanding which Chinese restaurant.
Section 0030
… the entity type identifier 120 may determine an entity type of “song” for the query “play the theme song from the titanic” based on the term “play” represented by the root of the semantic dependency tree for the query not representing an entity type and determining that the root has a child that represents the terms “the theme song” which does represent an entity type of “song.”
Once more we see reference to the action node being used to help clarify the type of top node being referenced.
Section 0034
… the entity type identifier 120 may additionally or alternatively determine an entity type based on extracting features from a query. The entity type identifier 120 may obtain the query and extract N-grams which define an entity type, e.g. “movie,” “song,” “river,” “mountain,” “who,” “where,” “person,” “guy,” etc. The entity type identifier 120 may determine an entity type based on whether the N-gram that defines an entity type is partially or completely included in a larger important N-gram, concept, or entity name from the query together with the relevance of that important N-gram, concept or entity to the query. For example, the entity type identifier 120 may determine that “river” is part of the entity name “Amazon river” so the query is less likely to be seeking an entity type of “river.”
In section 0034 we see the introduction of query features being used. In the example given, N-Grams may be used and this is another time that BERT would really lend a hand. The ability to predict the next word based on the previous becomes far more powerful when it can operate bidirectionally (or so I’m led to believe 🙂 )
This system would be used to refine probability. Creating different N-Gram models for different entity types, if their N-Gram predictions go smoothly, the probability of the system having selected the correct entity-type improves.
Section 0037
… the entity type identifier 120 may also determine a relevance threshold based on the entity type. The relevance threshold may indicate a confidence that an entity is relevant to a query seeking an entity of the particular type. For example, the relevance threshold for an entity type of “Chinese restaurant” may be less than a relevance threshold for an entity type of “restaurant” as the entity type of “restaurant” may include more entities than the entity type of “Chinese restaurant.” The entity type identifier 120 may determine a relevance threshold based on accessing a stored predetermined relevance threshold for each type of entity type. For example, the entity type identifier 120 may store a predetermined relevance threshold of 80% for an entity type of “restaurant” and a predetermined relevance threshold of 70% for “Chinese restaurant” and, in response to determining that a query is seeking a “Chinese restaurant,” identify the predetermined relevance threshold of 70% that is stored for the entity type “Chinese restaurant.”
Here we see reference to different thresholds of probability based on entity type. Essentially, lower thresholds where they is a lower chance or lower cost to inaccurate data.
Section 0043
In an example of using the user location data store 162, the entity identifier 130 may extract all the entities from a location history of the user which have a type identified by the entity type identifier 120, e.g., hotels, restaurants, universities, etc. along with extracting features associated to each such entity such as the time intervals when the user visited the entity or was near the entity, or how often each entity was visited or the user was near the entity.
In this section we see an obvious addition, your own data. The system will reference where you’ve been and for how long, so if you’re querying to call a Chinese restaurant on Piccadilly Street, and in your history there’s one you’ve been to (or perhaps near), that data would be used to increase the probability of one restaurant being the correct entity.
Section 0045
Locations relevant to the user may also be sent as part of the request, e.g., the current user’s location, the user’s home location, etc.
Another obvious addition to the system, the searchers current or key locations.
Section 0049
The subquery resolver 140 may partially resolve the query based on the entity that is identified. For example, the subquery resolver 140 may obtain an indication that the entity “China Gourmet” is identified by the terms “Chinese restaurant at Piccadilly Street 15” in the query “Call the Chinese restaurant on Piccadilly Street 15” and, in response, replace the terms with the name of the entity to obtain a partially resolved query of “Call China Gourmet.” The query may then be executed by the system 100. The system 100 may repeatedly resolve subqueries in a single query based on repeating partially resolving terms in the single query.
As we saw above in Section 0008, the system may change the query based on additional information. Once it has resolved that “the Chinese restaurant on Piccadilly Street 15” is “China Gourmet” it turns the query “Call the Chinese restaurant on Piccadilly Street 15” into “Call China Gourmet.”
As noted above, with supplemental databases, this would be far more effective.
That’s It
You made it!
Obviously, there are a lot of additional subtleties in the patent and it’s worth reading, but above we’ve covered the core of how this system (especially when combined with BERT, in my opinion) can be used to significant improve the user experience and probability of satisfying their queries.
This system is likely built to target voice queries based on many of the context and concepts discussed, but the impact of implementation is/will be/may be (such is the state of patent analysis) universal.
Thanks for covering the patent core. Thumbs up.